Weakly supervised learning from videos
Our research focuses on weakly supervised learning from unstructured Internet videos.
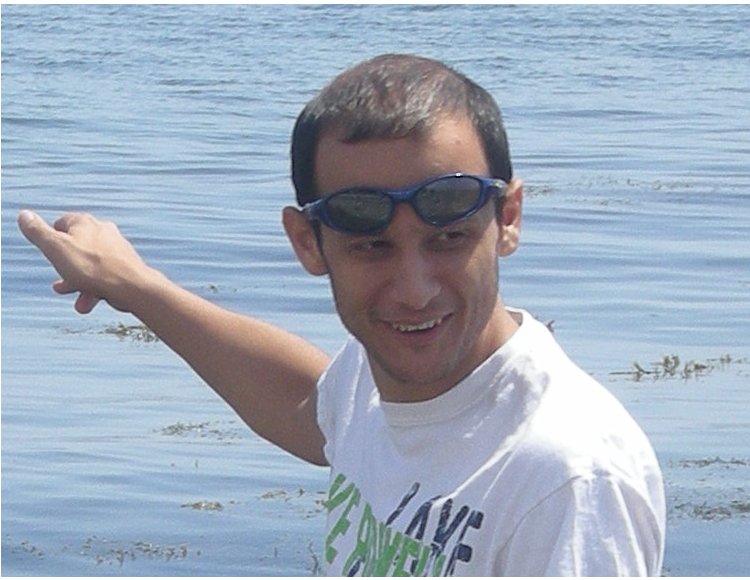
By reasoning about motion, we can discover many different properties of
object classes under very little human supervision.
These include the recurrent behaviors of the class, its visual aspects, its physical parts, as well as the spatiotemporal alignment between
different class instances in different videos (an example is shown on the left)
Behavior discovery and alignment
[IJCV 2016]
[CVPR 2015]
[Webpage]
[Dataset]
Phyisical part discovery
[CVPR 2016]
[Webpage + Dataset]
[TechCrunch article]
Visual aspect discovery
[
IMAVIS 2016]
Understanding images of indoor scenes
Our goal is to jointly understand the geometry and the semantics of indoor
scenes, such as bedrooms and kitches. We would like to infer what is where in 3D, by solving the problems of 3D reconstruction and object recognition jointly.
Doing this from a single 2D image also involves inferring the parameters of the camera. The image shows a fit for a bedroom, where the red lines denote the inferred room boundaries,
the green and the blue box are respectively a correctly identified
picture frame and a bed.
[CVPR 2013 paper]
[data]
[CVPR 2012 paper]
[data]
[CVPR 2011 paper]
[data]
[Dissertation]
Image and text alignment
Image keywords and captions provide information about what is in the image, but we do not know which words correspond to which image elements.
Our goal is to align words in the caption with visual features (see the main project
page).
My focus is on how to use specialized object detectors
for improving initial estimates of the alignment, as illustrated in the image on the left (click on it to enlarge).
[ACM MM 2011 paper]